
CLustering
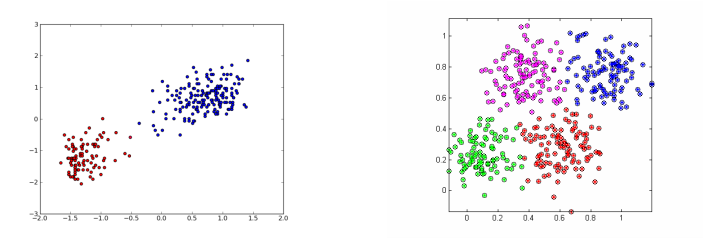
Both are versions of Clustering, but the image on the right shows more condense clusters of data.
Secondly, clustering techniques are used to group data to detect a possible outcome. This section causes further complications within data mining, because the results need to be grouped logically before being analysed.[1] K-means is used commonly because it functions easily and the main factor is the K centroids, which are present in each cluster. The position of the centroid is vital because during the process each centroid moves from their location and in doing so generates different results. Keeping a fair distance from one centroid to another optimizes results. Once in place datasets are placed near the closest centroid; and after the process new centroids are binded to the old set of data and continue to moves until it reaches a point. This creates the algorithm in ‘minimizing an objective function.’[2] Instead of K-means, search engines use TF*IDF in order to locate documents that are the most significant to the input data (question) first. Historians have credited the Inverse Document Frequency (IDF) by highlighting the experimental nature. However, when it is amalgamated with the Frequency of the Term (TF) it is advance in its, ‘text retrieval into methods for retrieval of other media, and into language processing techniques for other purposes.’ [3] This proves to be a good way of correlating data to provide maximum results.
[1]New, http://people.lis.illinois.edu/~unsworth/lyman.htm;
[2]New, http://people.lis.illinois.edu/~unsworth/lyman.htm;
[3] Stephen Robertson, Understanding Inverse Document Frequency: On theoretical arguments for IDF, Journal of Documentation, 60 no. vol. 5, pp. 503–520
