
Classification
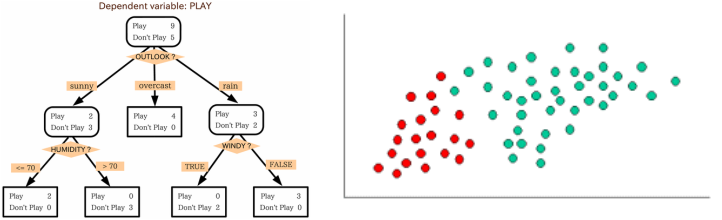
The image on the left shows a decision tree. The image on the right shows the simplest form of a Naïve Bayesian.
Classification is the first step in data mining; it contains different techniques in separating data depending on the variables. The tree method is notably used to draw up relations between these variables. When using the tree method the facts gathered from a range of databases are divided into categories. These are further divided until each group contains only a few factors and has created many branches in the process. A limit is needed to prevent ‘overfitting;’ where categories divide repeatedly leaving as little as one factor within it, this is one of the dangers and disadvantages in the decision tree methodology. For analytical evaluation the tree primarily highlights key variables.[1] This means that it would be quick and easy to locate variables that had initially branched out, thus showing their immediate importance in relation rather than further down on the second or third branch. Interestingly, Classification and Regression Trees (CART) and Chi Square Automatic Interaction Detection (CHAID) are techniques within the decision tree that has accepted unclassified data in creating new predictions.[2] Another type of classification is the Naïve Bayesian, which is predominantly reliable and specifically deals with textual data.[3] This is different to the decision tree in one fundamental way; the Naïve Bayesian is based on subjunctive probability. This means that instead of categorizing words based on their association to each other, the Bayesian system relies on the number of times the word appears or does not appear in the text. The extent in which this type of Text mining is useful for historians or a researcher is debatable. The algorithms would create more results in searching for a word, yet the relevance of the search may not always be practical because words may have more than one significant connotation; meaning some results will be unrelated to the question. Matt Kirschenbaum applied analytical data to poems written by Emily Dickinson. He used the Naïve Bayesian method to compare whether the system could detect an erotic poem or not, compared to Scholarly standards. He argued that if technology proved to be effective then it would confirm the information scholars already possessed.[4] This may be the case but it does not produce new and exciting relationships to debate about, or spark a new outlook to be discussed. [1]Data mining for process improvement, http://www.crosstalkonline.org/storage/issue-archives/2011/201101/201101-Below.pdf; consulted 15 April 2012
[2]Data, http://www.anderson.ucla.edu/faculty/jason.frand/teacher/technologies/palace/datamining.htm;
[3]New Methods for Humanities Research; http://people.lis.illinois.edu/~unsworth/lyman.htm; consulted 15 April 2012
[4] New Methods for Humanities Research; http://people.lis.illinois.edu/~unsworth/lyman.htm; consulted 15 April 2012
